Attention Is All You Need · Attention Is All You Need · 3 min read
Results and lasting impact
The transformer was not just a theoretical improvement. It set new state-of-the-art results on standard benchmarks while using less compute than the models it replaced. More significantly, it established an architectural foundation that every major language model since has built on.
BLEU scores
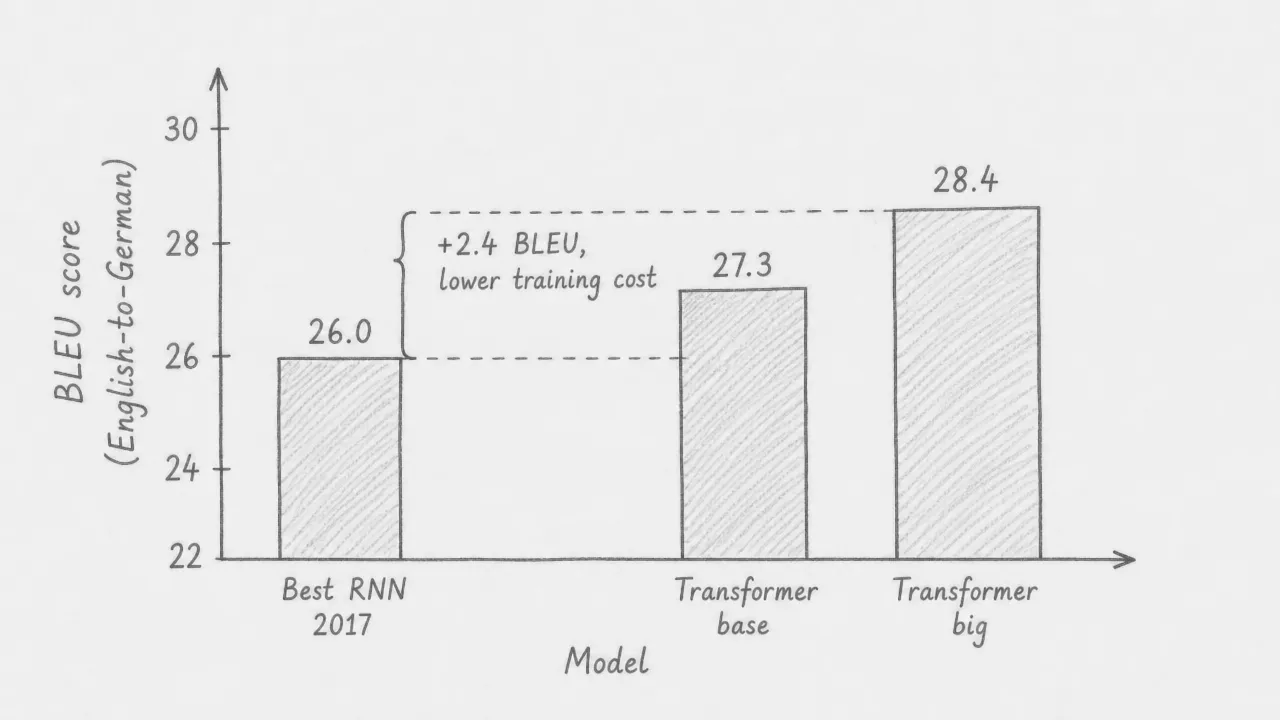
BLEU (Bilingual Evaluation Understudy) is a standard metric for translation quality. It measures how closely a model’s output matches human reference translations, on a scale where higher is better. On the WMT 2014 English-to-German task, the best prior model scored 26.0. The Transformer base scored 27.3 and the Transformer big scored 28.4, an improvement of 2.4 BLEU points over the previous best. Both transformer variants achieved these results with lower training cost than the models they outperformed.
Training cost

The paper reports training costs in floating point operations (FLOPs). The best prior models, including convolutional sequence-to-sequence architectures, required significantly more compute to reach lower BLEU scores. The Transformer base model used roughly one tenth the FLOPs of the strongest prior model. The Transformer big used more compute than the base model but still less than prior SOTA, while achieving the highest score. The result was a better accuracy-to-cost ratio than anything that preceded it.
What the transformer unlocked
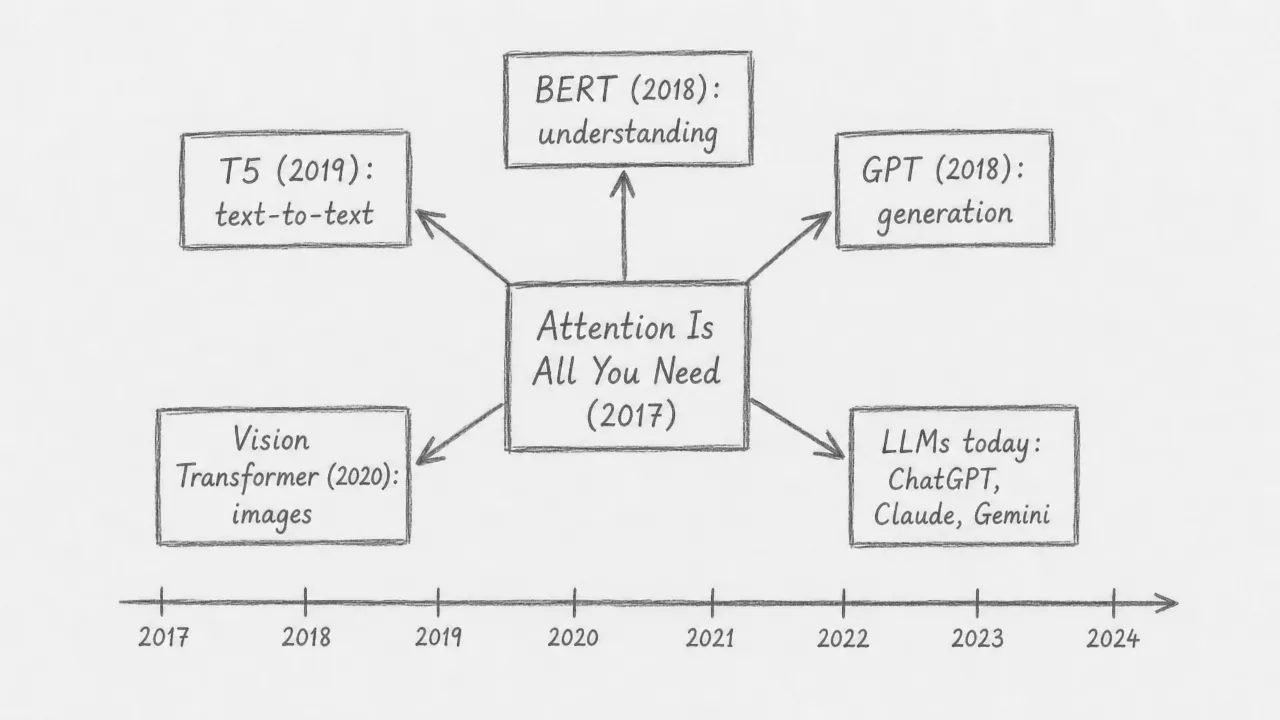
The transformer’s influence extended far beyond translation. Within a year, BERT (2018) applied the encoder stack to language understanding tasks, and GPT (2018) applied the decoder stack to text generation. T5 (2019) unified both directions under a text-to-text framework. The Vision Transformer (2020) showed that the same architecture could process images by treating patches as tokens. Every large language model in use today, including GPT-4, Claude, and Gemini, is a direct descendant of the architecture introduced in this paper. The core components, attention, residual connections, layer normalization, and feed-forward layers, remain essentially unchanged.