Attention Is All You Need · Attention Is All You Need · 3 min read
The transformer at a glance
The transformer takes a source sentence and produces a target sentence. Internally it does this in two stages: an encoder that reads the input, and a decoder that writes the output. Both stages are built from the same repeating layer design, stacked six times each.
Input and output
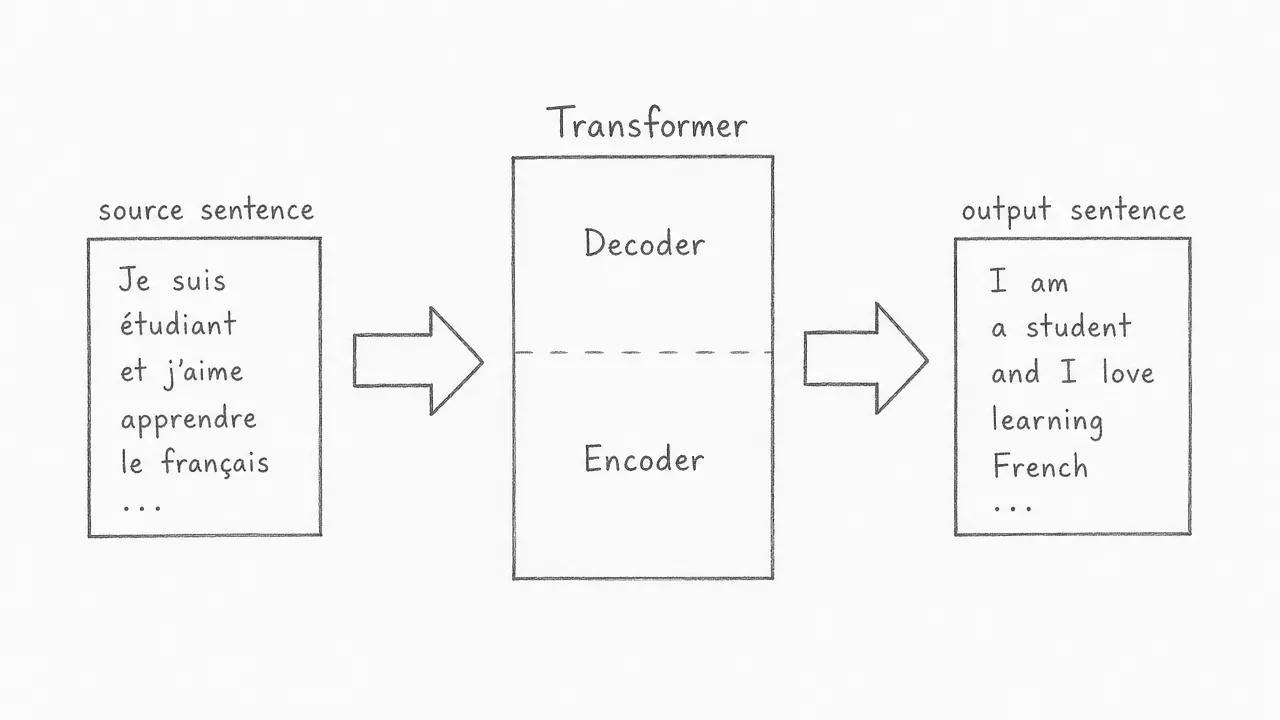
The transformer was designed for sequence-to-sequence tasks. In the original paper, the task is translation: a French sentence goes in, an English sentence comes out. The encoder reads the entire source sentence at once and builds a rich internal representation of it. The decoder then uses that representation to produce the output, one token at a time.
Encoder and decoder stacks
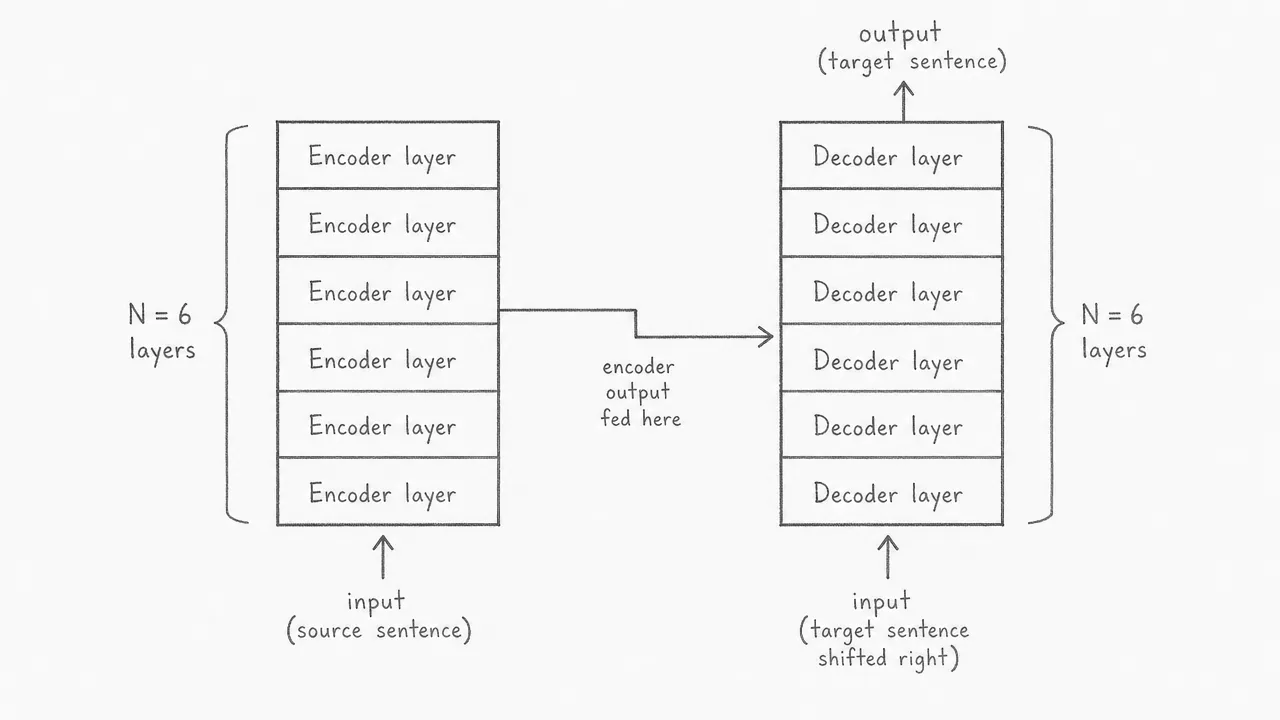
Both the encoder and the decoder are stacks of identical layers. The paper uses N = 6 layers in each stack. Every encoder layer refines the representation of the input. The final encoder layer passes its output to every decoder layer through a connection called cross-attention. The decoder also receives the target sentence as input, but shifted one position to the right, so it can only see tokens it has already produced.
What flows through
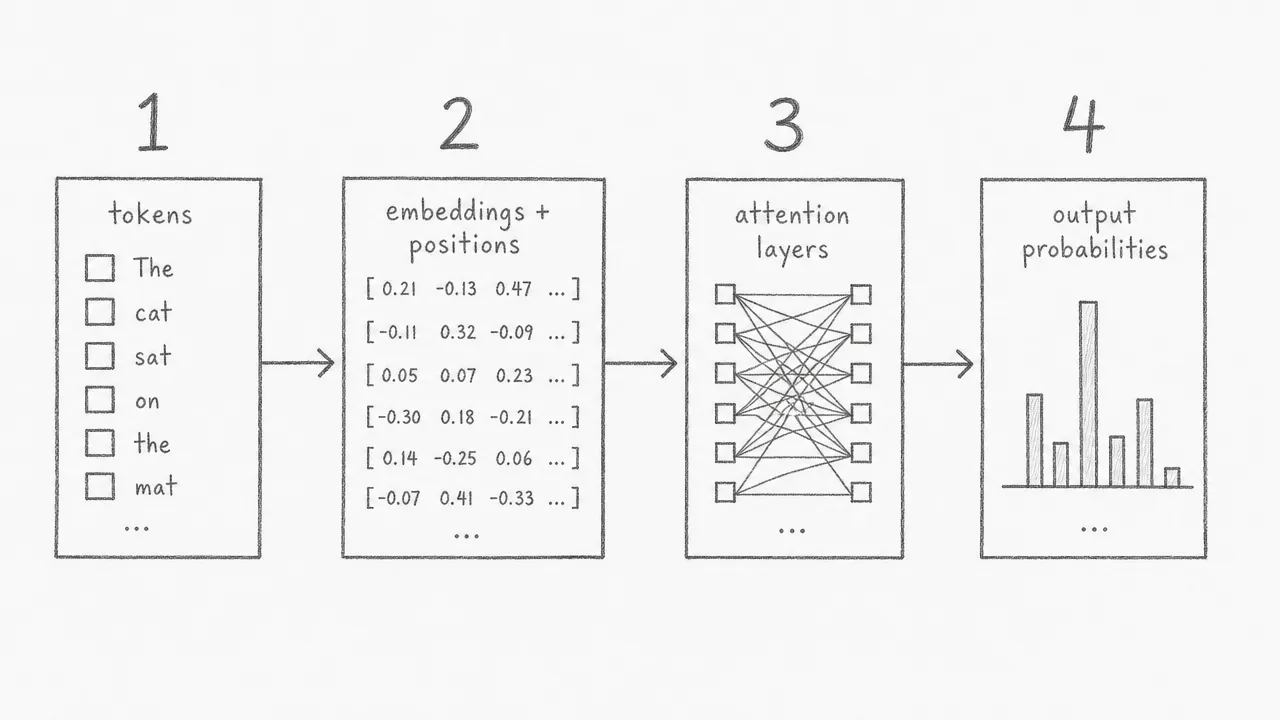
Data moves through the transformer in four steps. First, the input sentence is split into tokens (words or subwords). Second, each token is converted into a vector of numbers called an embedding, and a positional signal is added so the model knows the order of tokens. Third, these vectors pass through the attention layers, where each token gathers information from all other tokens. Fourth, the decoder produces a probability distribution over the vocabulary at each position, and the highest-probability token is selected as the next output word.