Attention Is All You Need · Attention Is All You Need · 3 min read
Input representation
Before any attention can happen, the transformer needs to convert raw text into numbers. It does this in two steps: first it looks up a learned vector for each token, then it adds a positional signal so the model knows where each token sits in the sequence.
From token to vector
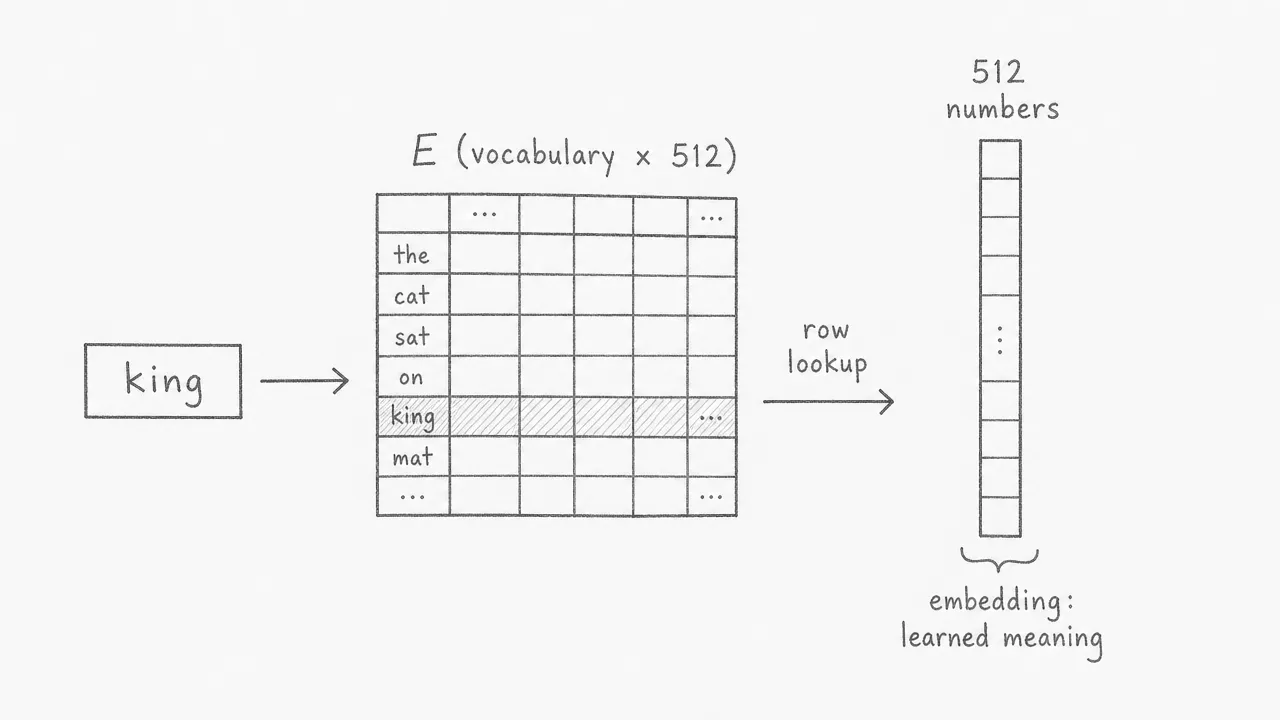
The transformer maintains an embedding matrix of shape , where is the vocabulary size and is the model dimension (512 in the base transformer). Each row of corresponds to one vocabulary item. When the model sees the token “king”, it retrieves the corresponding row from . This row is a vector of 512 numbers, and its values are learned during training to capture the meaning of the word. No handcrafted features are used: the model discovers what each position in the vector should encode on its own.
Adding position
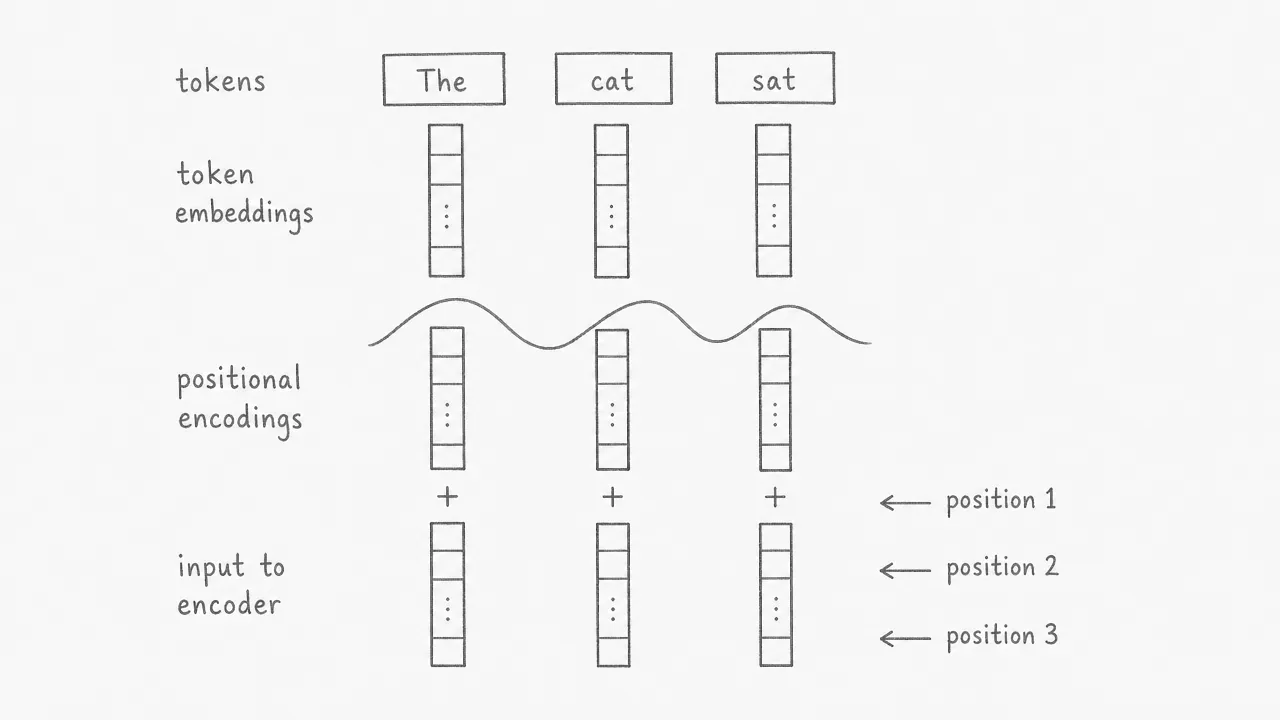
Attention processes all tokens simultaneously, which means it has no built-in sense of order. To fix this, the transformer adds a positional encoding to each token embedding before the input enters the encoder. The positional encoding is a vector of the same dimension as the embedding. The two vectors are added element-wise. The result carries both the meaning of the token and the information about where it appears in the sequence.
The paper uses sine and cosine functions at different frequencies to generate positional encodings. Each position gets a unique pattern of values, and nearby positions get similar patterns. This allows the model to reason about both absolute position and relative distance between tokens.
Why position must be injected explicitly
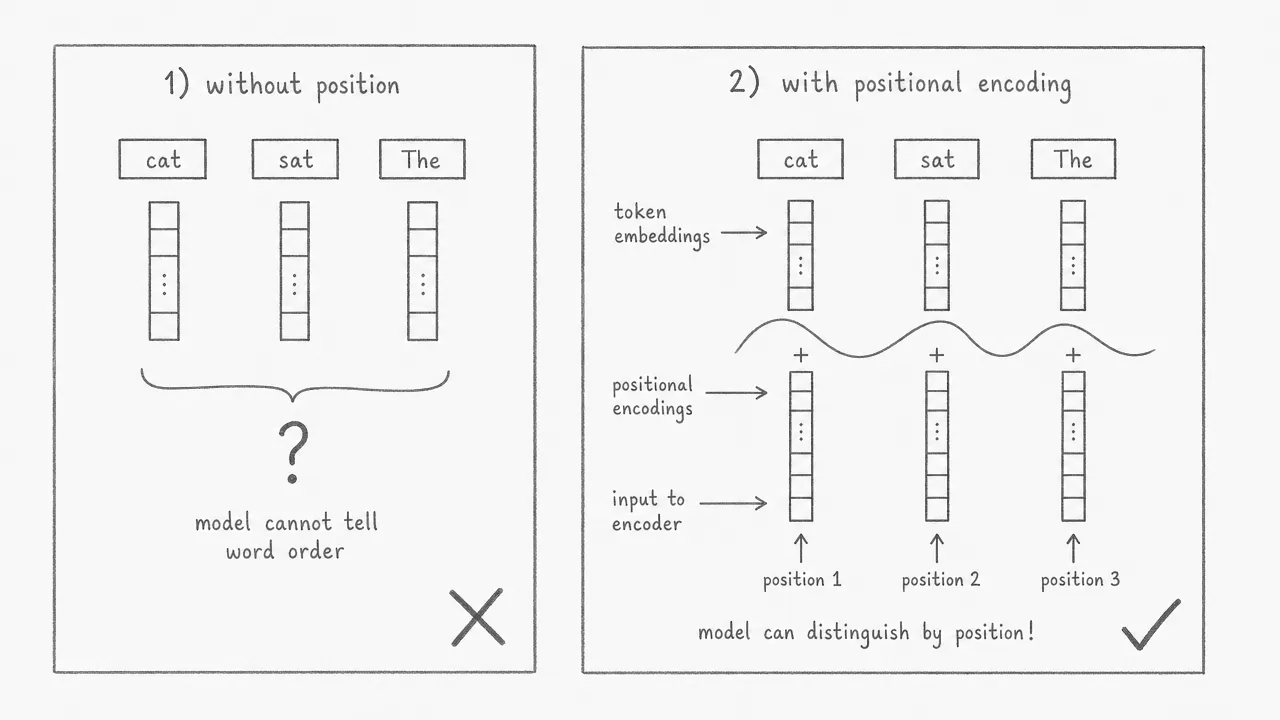
Without positional encodings, the transformer would treat “The cat sat” and “sat cat The” as identical inputs, because attention computes relationships between tokens without regard to their order. The embedding vectors for the same word are always the same, regardless of where the word appears. Adding a unique positional signal for each index breaks this symmetry. Even if tokens arrive in a shuffled order, each one carries its correct position index, and the model can reconstruct the intended sequence.