Attention Is All You Need · Attention Is All You Need · 3 min read
Multi-head attention
A single attention operation computes one set of relationships across the sequence. But a sentence contains many different kinds of relationships simultaneously: grammatical agreement, causal links, coreference, proximity, and more. Multi-head attention runs several attention operations in parallel, each with its own learned projections, so the model can capture multiple relationship types at once.
One head vs eight heads
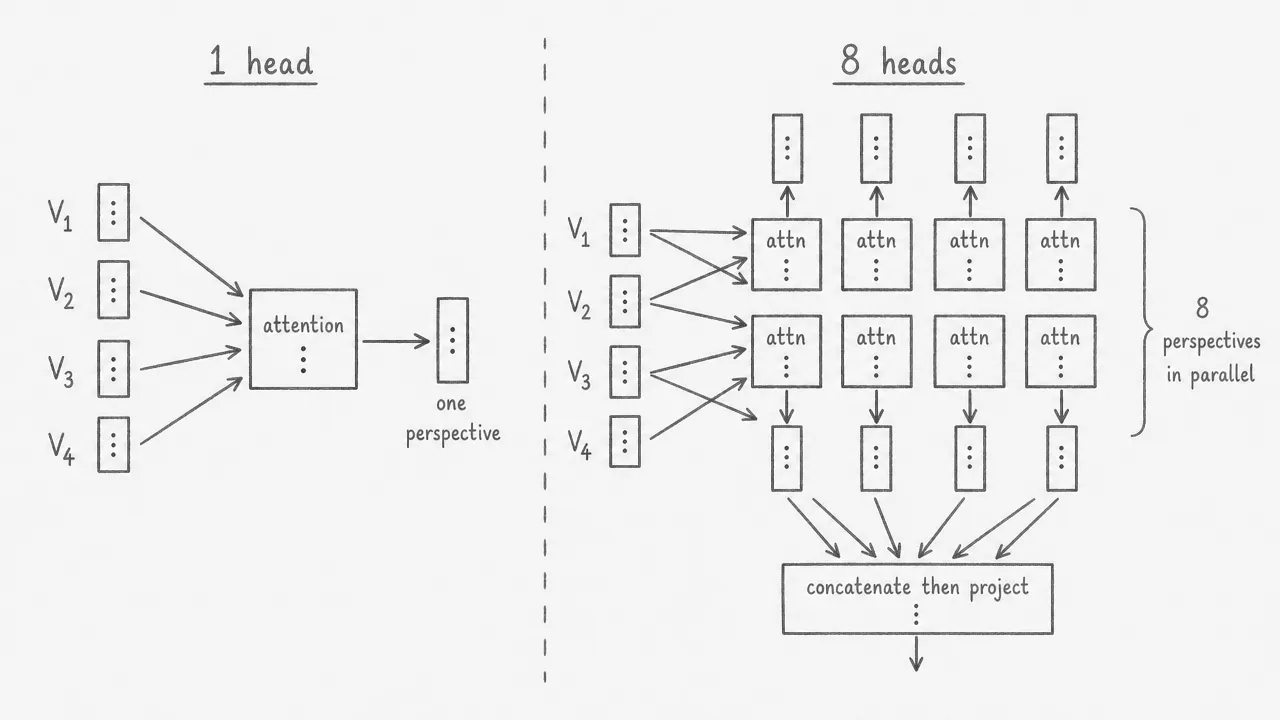
In the base transformer, the model runs attention heads in parallel. Each head receives the same input but applies its own learned query, key, and value projection matrices. Because the projections differ, each head attends to the sequence in a different way. The outputs of all eight heads are concatenated and passed through a single linear projection to produce the final multi-head attention output.
To keep the total computation comparable to a single full-dimension attention, each head operates in a reduced dimension . So eight heads of dimension 64 together cover the same parameter budget as one head of dimension 512.
What different heads learn
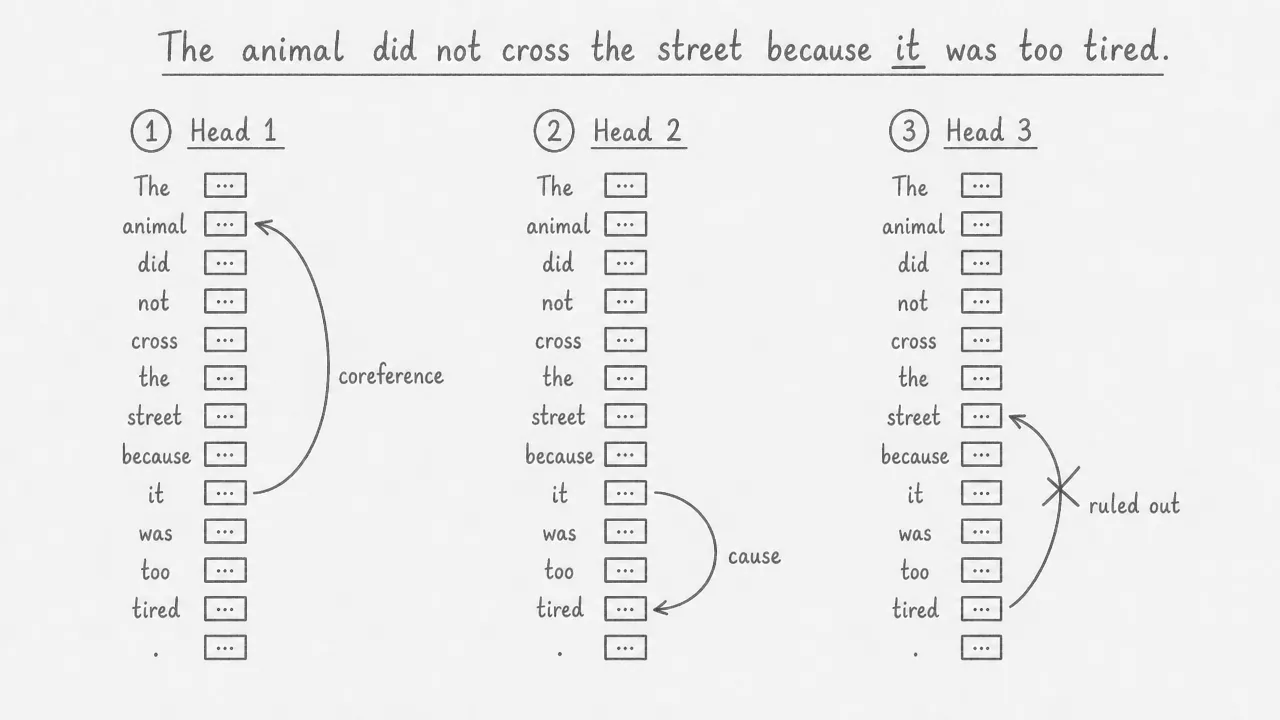
Each head specializes during training without being explicitly told what to look for. In practice, different heads tend to capture different linguistic relationships. For the word “it” in the sentence “The animal did not cross the street because it was too tired”, one head may learn to link “it” back to “animal” (resolving what “it” refers to), another may link “it” to “tired” (the reason it did not cross), and another may learn that “street” is not the correct referent. No supervision directs this specialization: it emerges from the training objective alone.
Concatenation and final projection
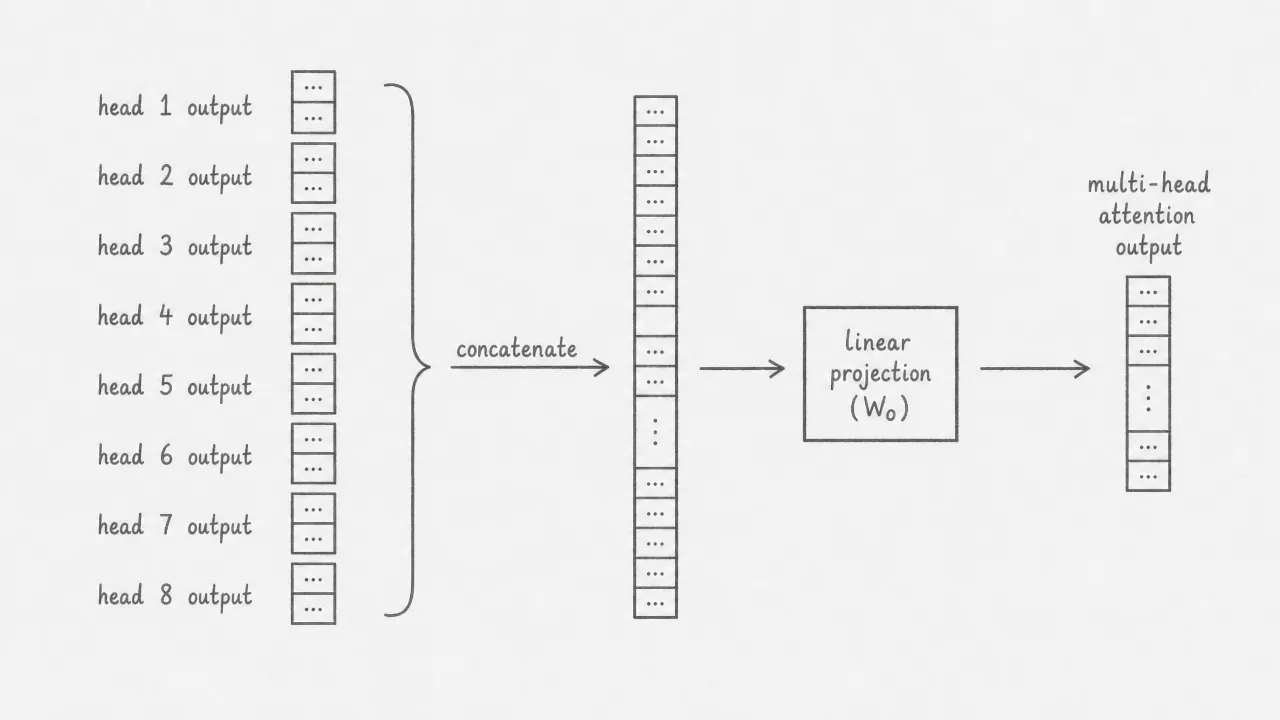
After all eight heads compute their outputs, the results are concatenated into a single long vector of dimension . This concatenated vector is then multiplied by the output projection matrix , which has shape . The projection mixes information across all heads and produces the final multi-head attention output, which has the same shape as the original input. This shape invariance is what allows the same block design to be stacked repeatedly in the encoder and decoder.