Attention Is All You Need · Attention Is All You Need · 3 min read
The decoder
The decoder generates the output sequence one token at a time. It receives two inputs: the tokens it has already produced, and the encoder’s output. It uses three sublayers per layer to combine these two sources of information and produce a probability distribution over the vocabulary at each position.
Masked self-attention
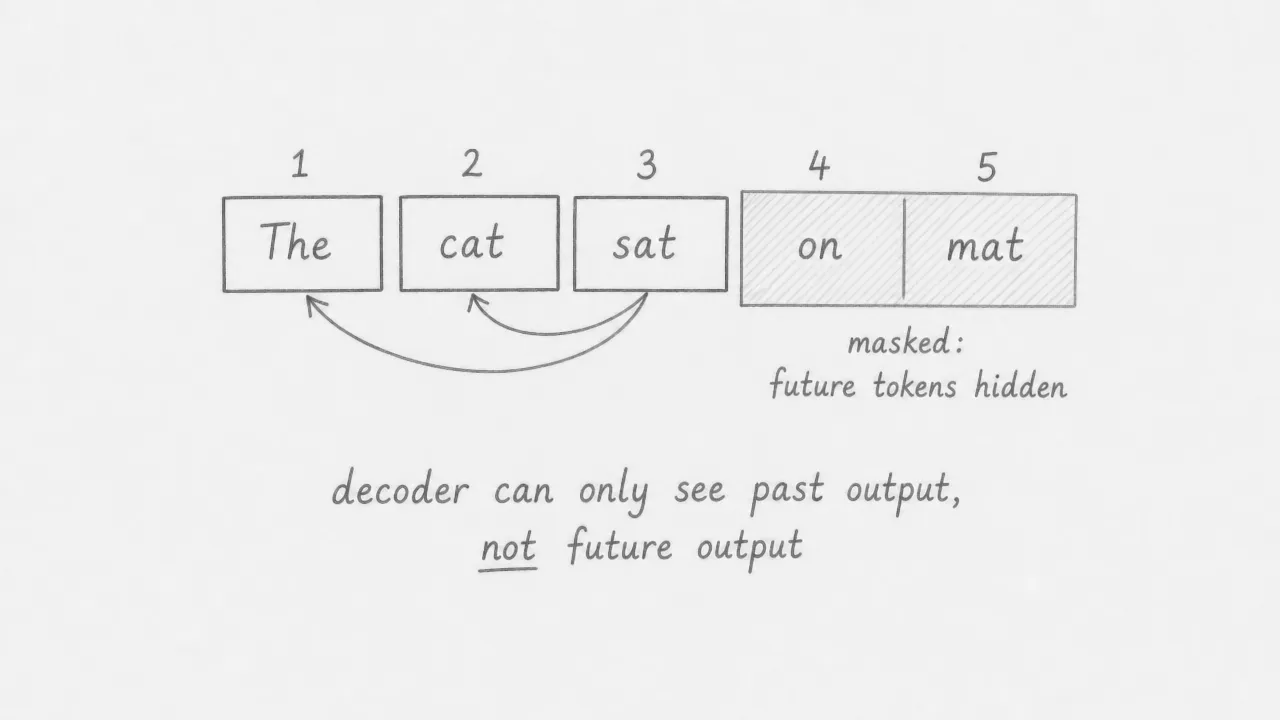
The first sublayer in each decoder layer is masked multi-head self-attention. It works like encoder self-attention, except that tokens cannot attend to positions that come after them in the sequence. This is enforced by setting the attention scores for future positions to negative infinity before the softmax, which makes their weights collapse to zero.
The mask is necessary for two reasons. During training, the decoder receives the entire target sentence at once (for efficiency), so without masking it could simply copy future tokens rather than learning to predict them. During inference, future tokens do not exist yet, so the mask reflects reality: the model can only use what it has already generated.
Cross-attention
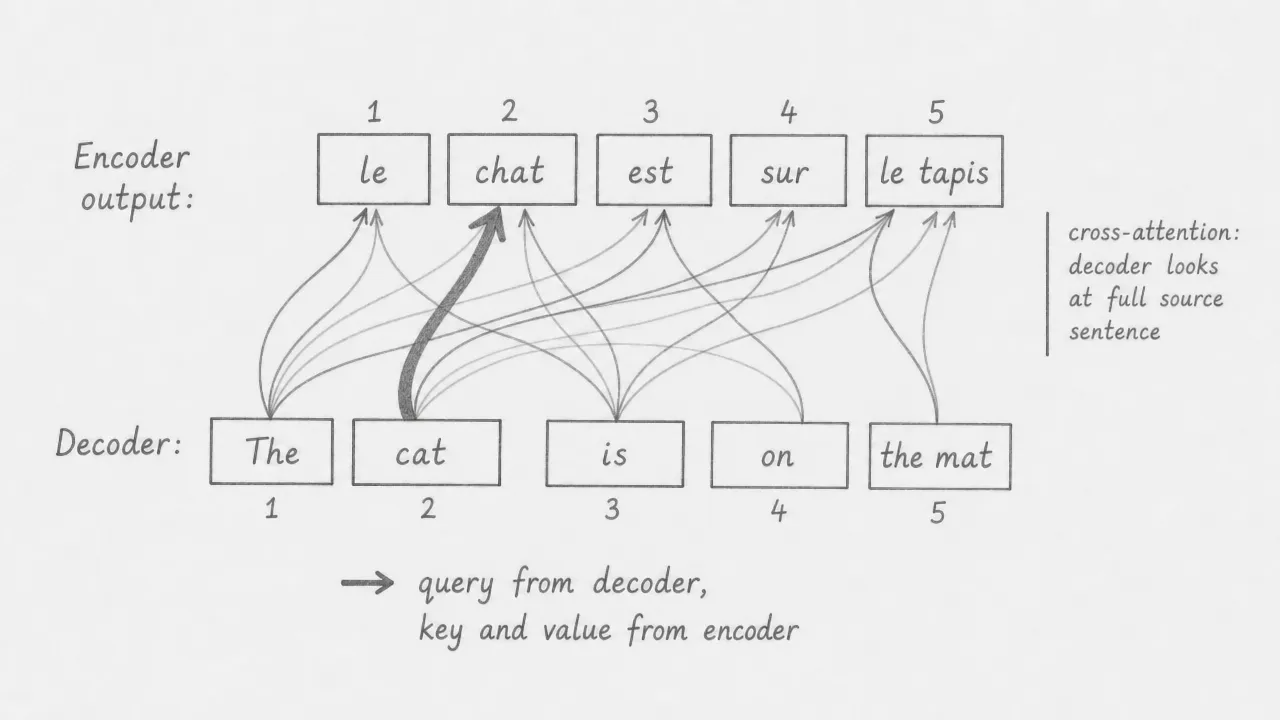
The second sublayer is cross-attention. This is where the decoder reads the encoder’s output. The query comes from the decoder’s current representations. The keys and values come from the encoder’s final output. The decoder token “cat” generates a query that attends most strongly to the encoder token “chat”, because their representations are most compatible. This is how the decoder aligns the output it is generating with the relevant parts of the source sentence.
Unlike masked self-attention, cross-attention is unrestricted: each decoder position can attend to any position in the encoder output, including positions before and after it in the source sequence.
Full decoder layer
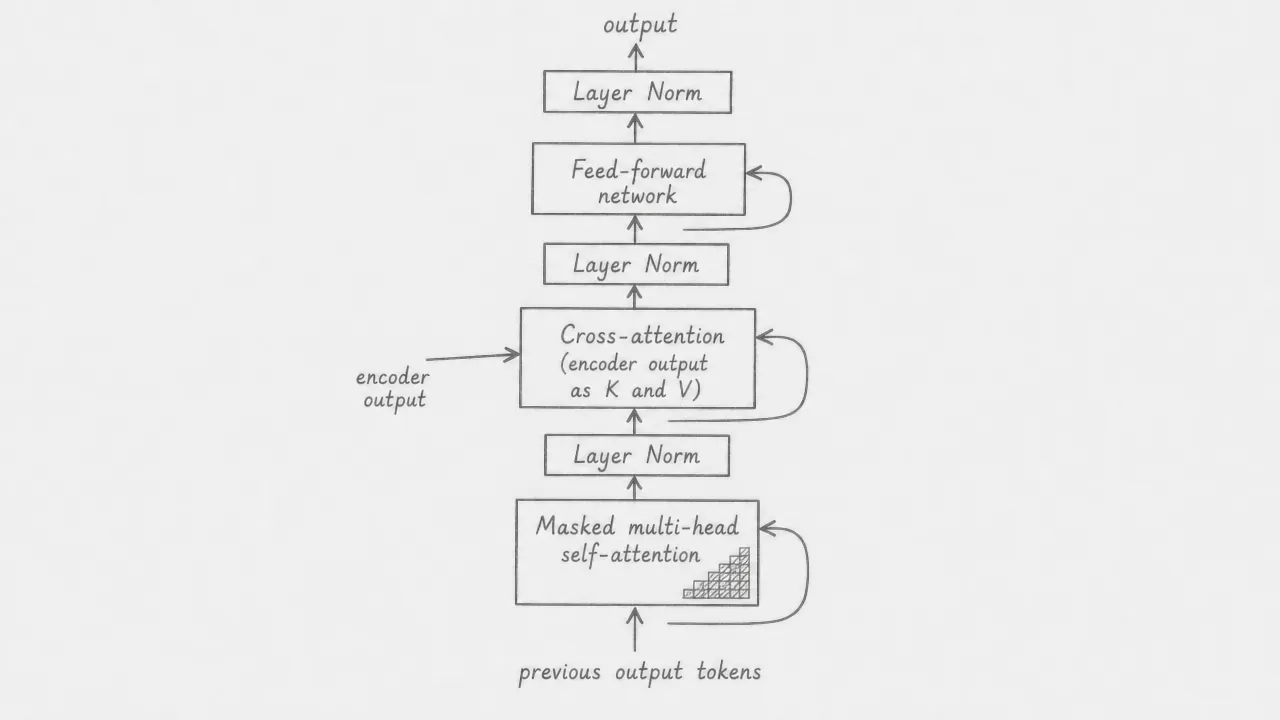
Each decoder layer applies all three sublayers in sequence, each followed by add-and-norm: masked self-attention, cross-attention, and feed-forward network. This gives the decoder layer three add-and-norm steps, one more than the encoder layer. The residual connections wrap each sublayer, so the input to each sublayer is added back to its output before normalization. Six of these layers are stacked, and the output of the final layer is passed to the linear projection and softmax that produce the next token prediction.