Attention Is All You Need · Attention Is All You Need · 3 min read
Scaled dot-product attention
Attention is the mechanism that lets every token gather information from every other token. It does this by computing a score between each pair of tokens, converting those scores into weights, and using the weights to mix together a set of information vectors. Three vectors drive the whole process: a query, a key, and a value.
Query, key, and value
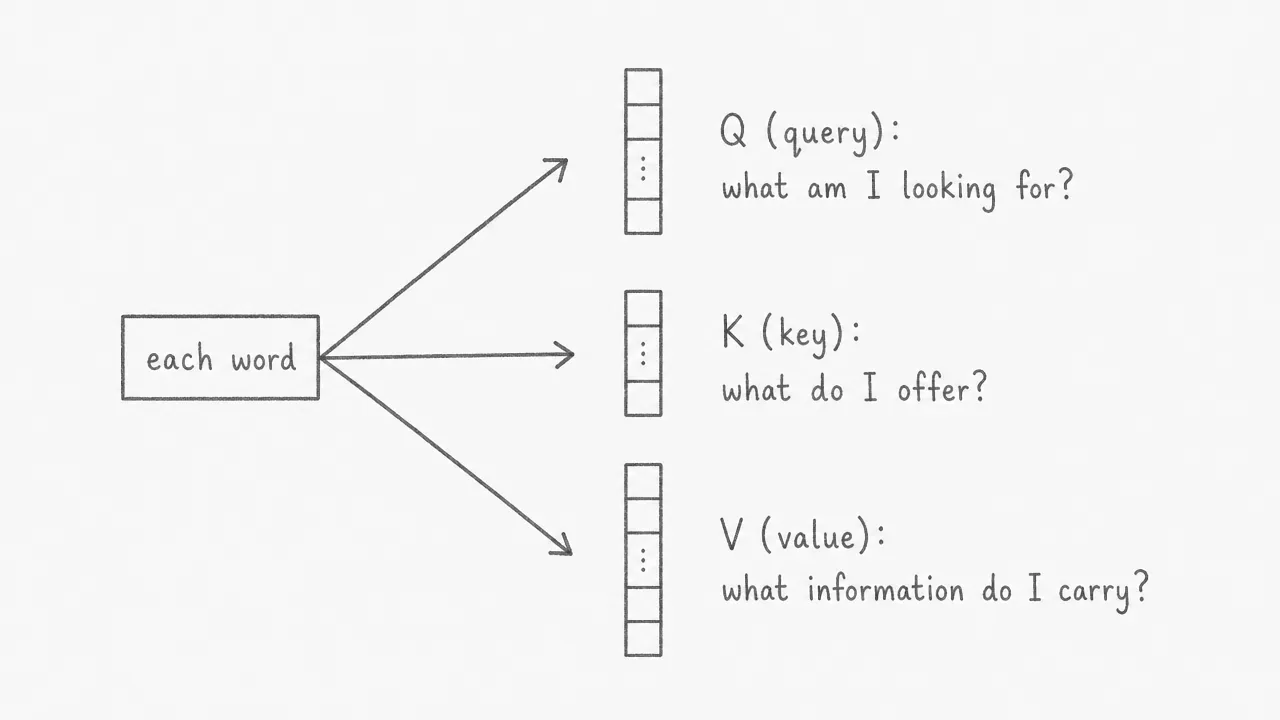
Every token in the sequence is transformed into three separate vectors by multiplying its embedding with three learned weight matrices. The query represents what the token is searching for in the rest of the sequence. The key represents what the token advertises about itself. The value carries the actual content that will be passed on if another token attends to this one. These three projections are independent: each is learned separately during training.
Computing attention weights
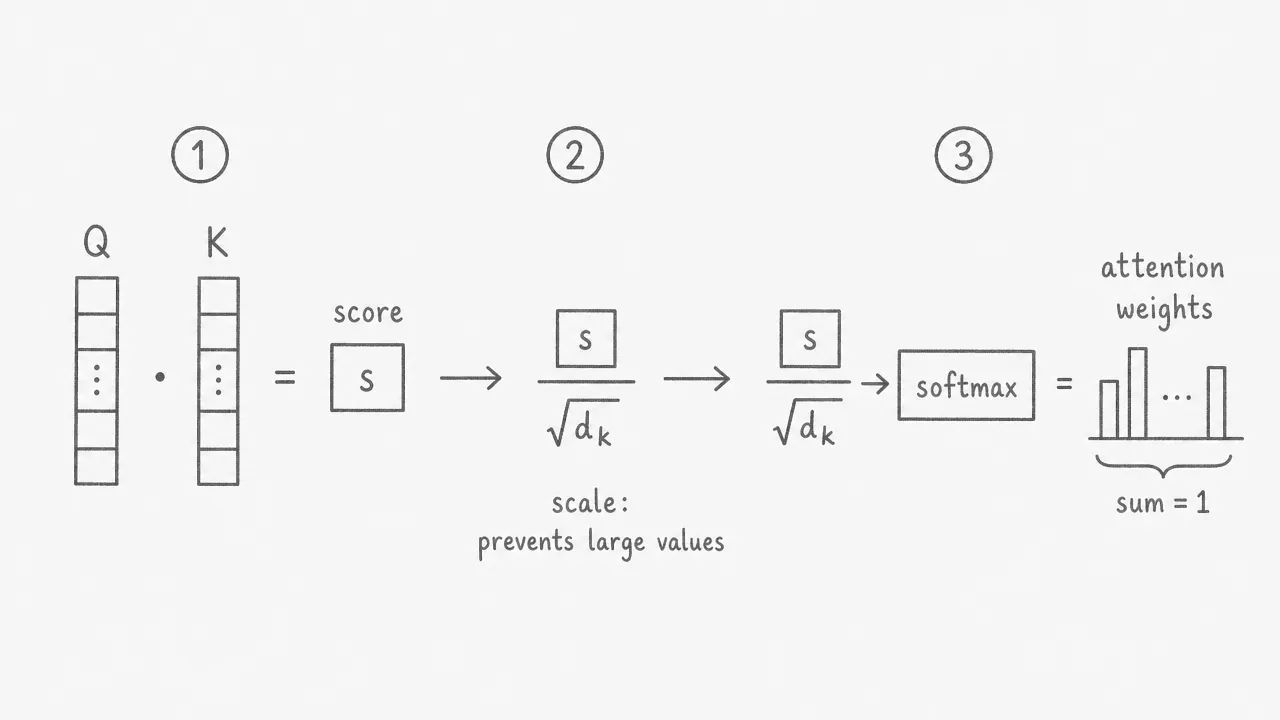
To decide how much attention token should pay to token , the model computes the dot product of their query and key vectors. A larger dot product means the two tokens are more compatible. The result is a raw score , where is the query of token and is the key of token .
This score is then divided by , where is the dimension of the key vectors. Without this scaling step, dot products in high-dimensional spaces tend to grow very large, pushing the softmax output toward extreme values close to 0 or 1 and making gradients vanish during training. Dividing by keeps the scores in a stable range.
The scaled score passes through a softmax function, which converts the full set of scores for token across all other tokens into a probability distribution. Every weight is between 0 and 1, and all weights sum to exactly 1. This is the complete formula:
where is the matrix of query vectors, is the matrix of key vectors, is its transpose, is the key dimension, and is the matrix of value vectors.
Weighted sum over values
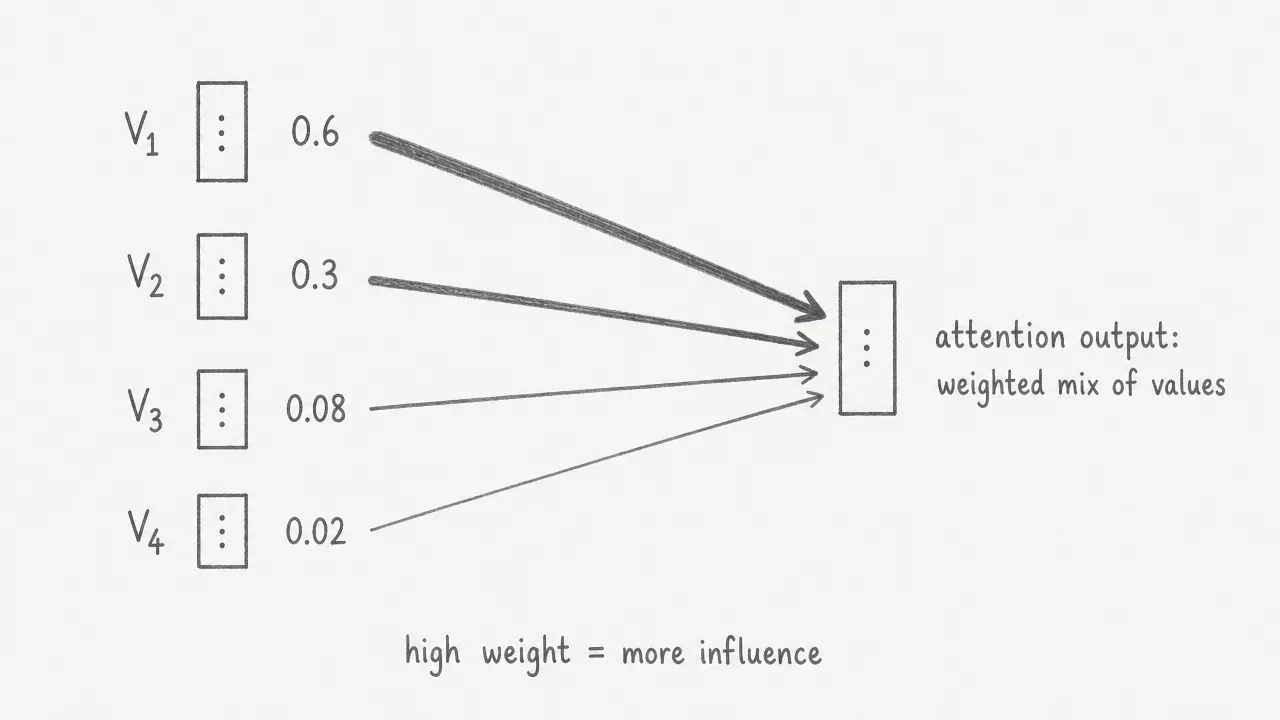
The attention weights are applied to the value vectors. Each value vector is multiplied by its corresponding weight, and the results are summed. A token with weight 0.6 contributes much more to the output than a token with weight 0.02. The final result is a single vector that is a weighted mixture of all value vectors in the sequence. This is the attention output for token : a new representation that blends information from across the entire sequence, with each source weighted by how relevant it was judged to be.