Attention Is All You Need · Attention Is All You Need · 3 min read
The problem with RNNs
Before the transformer, sequence models like RNNs (Recurrent Neural Networks) were the standard approach for tasks like translation. They had two structural problems that limited how well they could work.
The transformer replaces sequential processing with attention, letting every word look directly at every other word in a single step.
Words must wait their turn
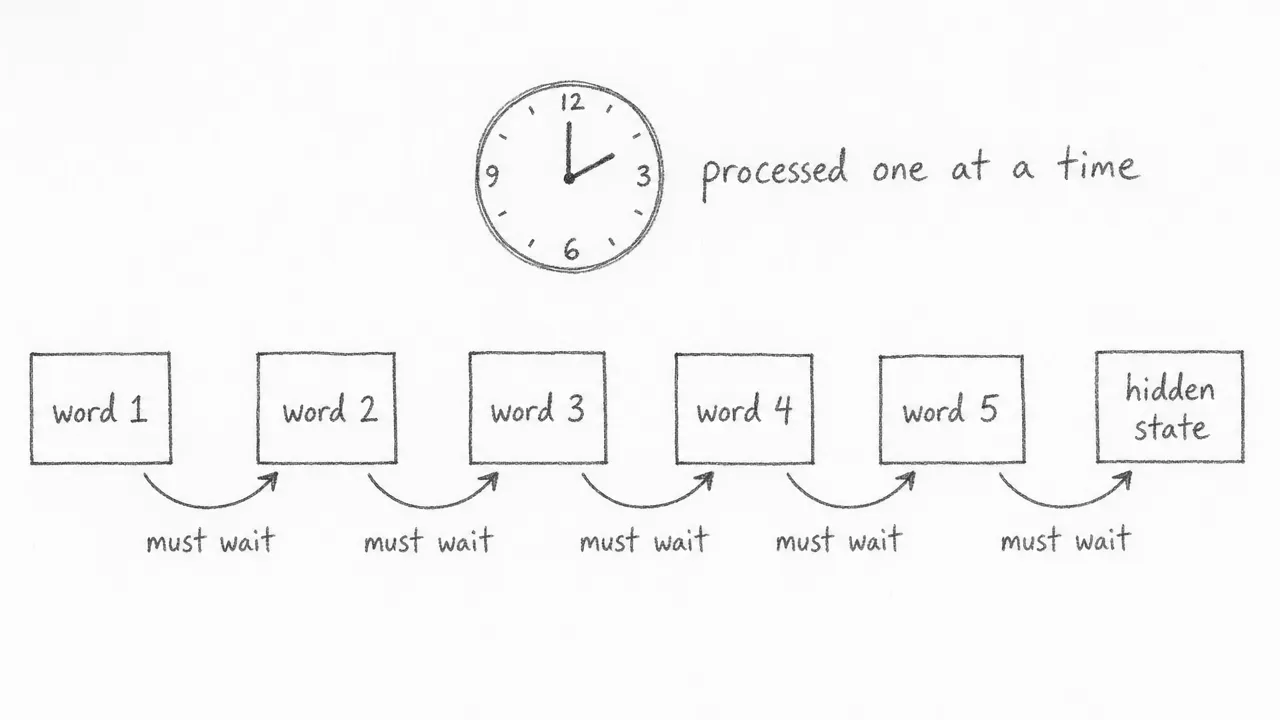
A language model translating a sentence needs to read every word before producing output. In an RNN, this happens strictly in order: word 1 is processed, its result is passed to word 2, word 2’s result is passed to word 3, and so on. No step can begin until the previous step finishes. For a sentence of 100 words, that is 100 sequential operations with no way to run them in parallel.
Long sentences lose information
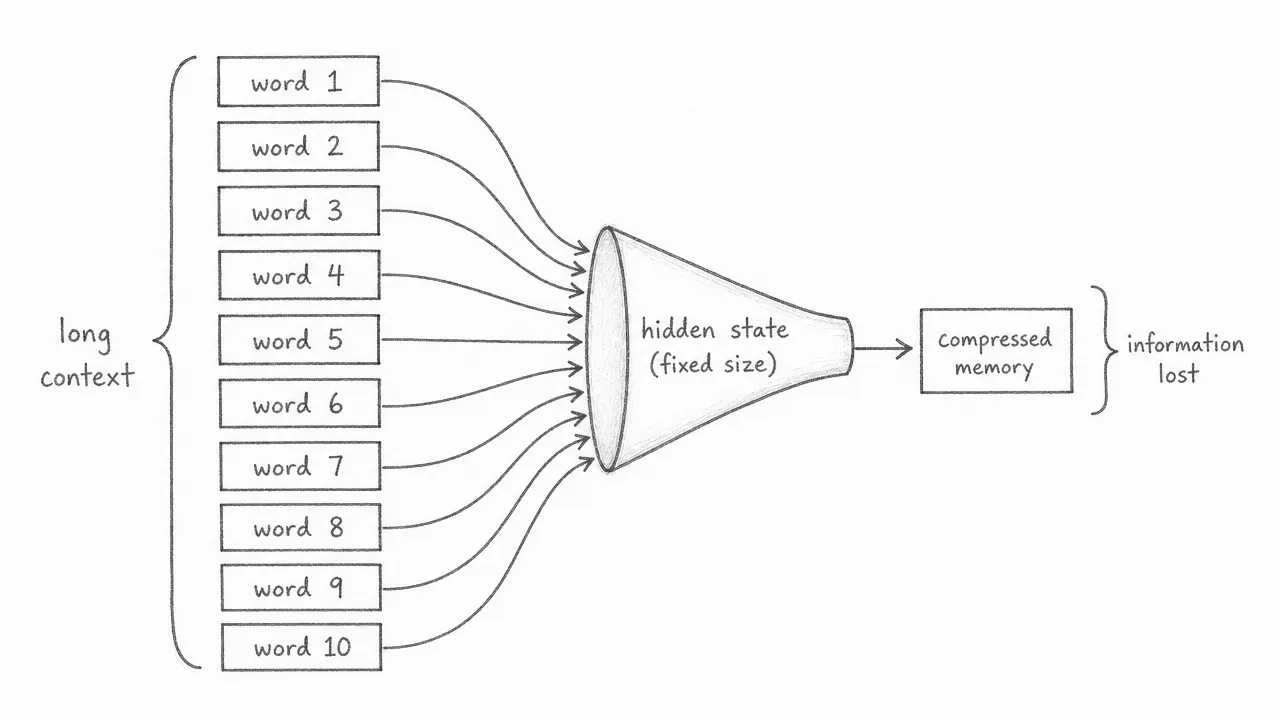
At the end of the chain, the RNN must summarize everything it has read into one fixed-size vector called the hidden state. This vector has a set number of dimensions regardless of how long the input sentence is. A 5-word sentence and a 50-word sentence both produce a hidden state of the same size. The longer the sentence, the more information gets discarded. Words from the beginning of a long sentence are often poorly represented by the time the hidden state is used.
The transformer removes both problems
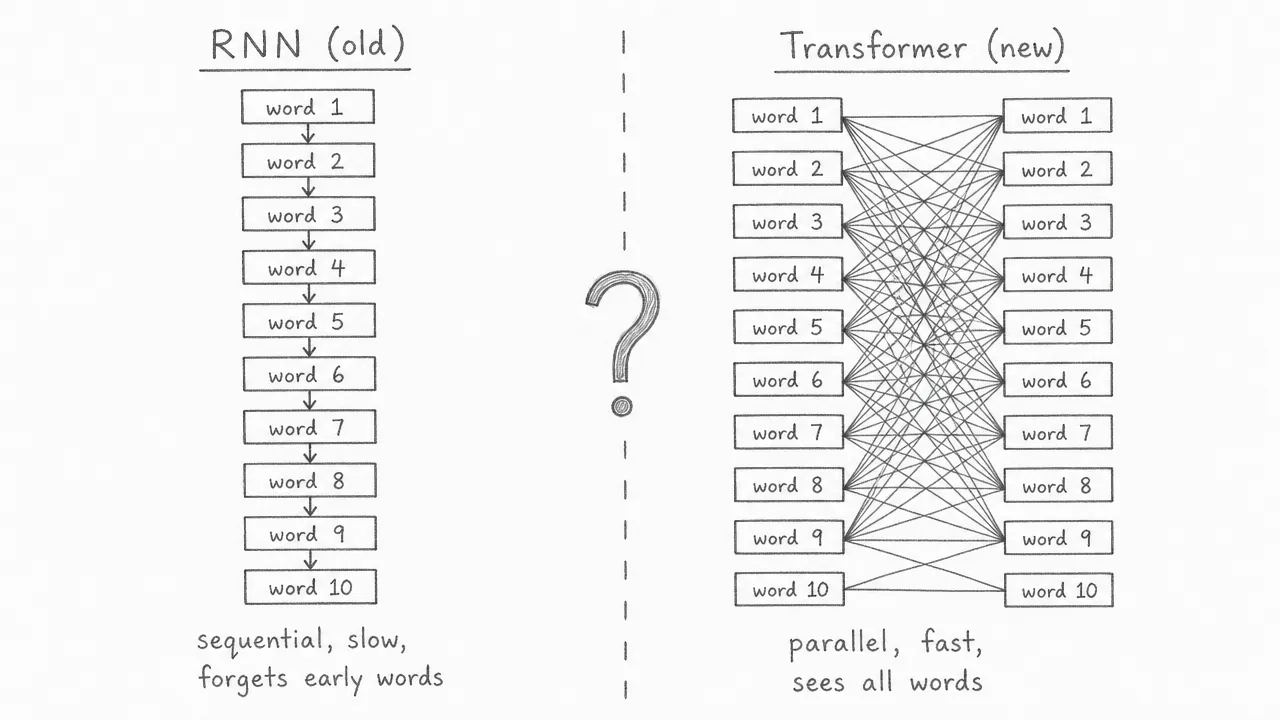
The transformer replaces the sequential chain with attention: a mechanism that lets every word look directly at every other word in a single step. There is no sequential dependency, so all words can be processed at the same time. And because no information passes through a fixed-size bottleneck, the model retains access to every word equally, regardless of where it appears in the sentence. The sections that follow explain exactly how attention makes this possible.