Attention Is All You Need · Attention Is All You Need · 3 min read
The encoder
The encoder reads the entire input sequence and converts it into a set of contextual vectors, one per token. These vectors are not simple lookups: by the time a token reaches the top of the encoder stack, its representation has been shaped by every other token in the sequence. This is what makes the encoder’s output useful for the decoder.
One encoder layer
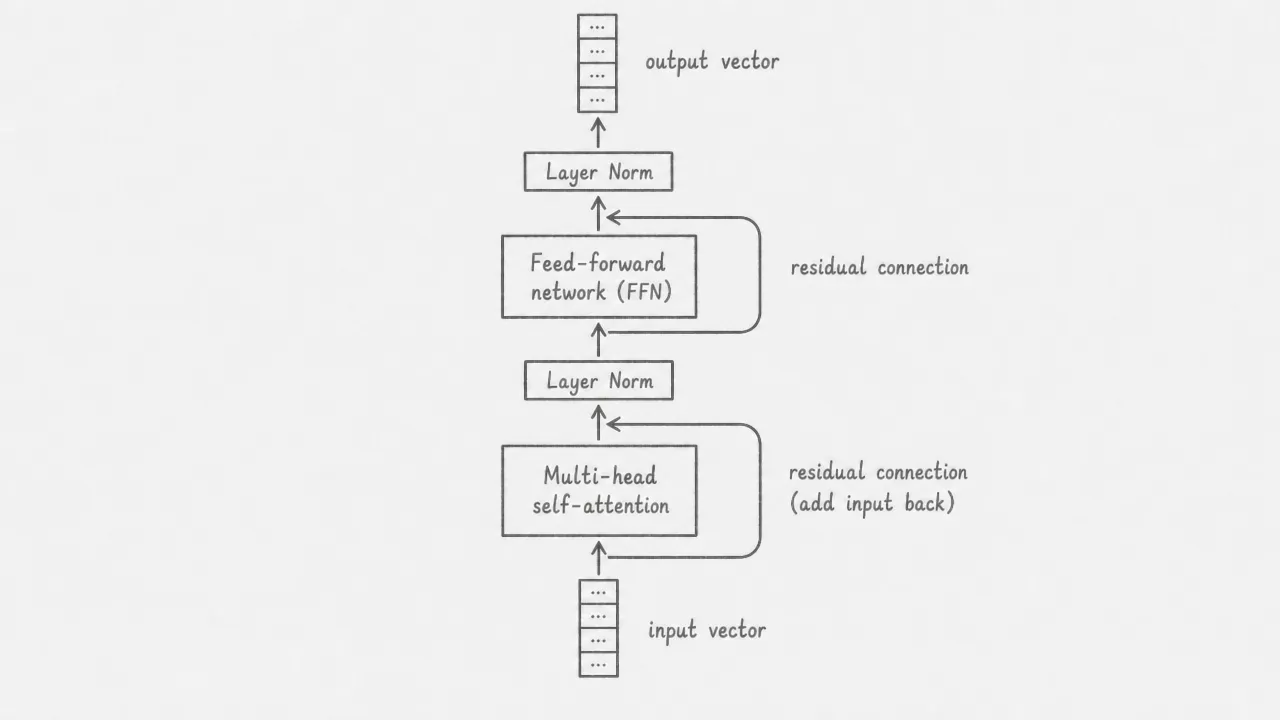
Each encoder layer contains two sublayers. The first is multi-head self-attention, which lets every token gather information from the full sequence. The second is a feed-forward network (FFN), which applies the same two-layer transformation independently to each token’s vector. The FFN expands the dimension to 2048, applies a ReLU activation, then projects back to 512.
Both sublayers are wrapped with a residual connection: the input to the sublayer is added back to the sublayer’s output before passing to the next step. This is written as , where is the sublayer input, is the result of attention or FFN, and normalizes the sum. Residual connections allow gradients to flow directly through the network during training, making deep stacks trainable.
Self-attention inside the encoder
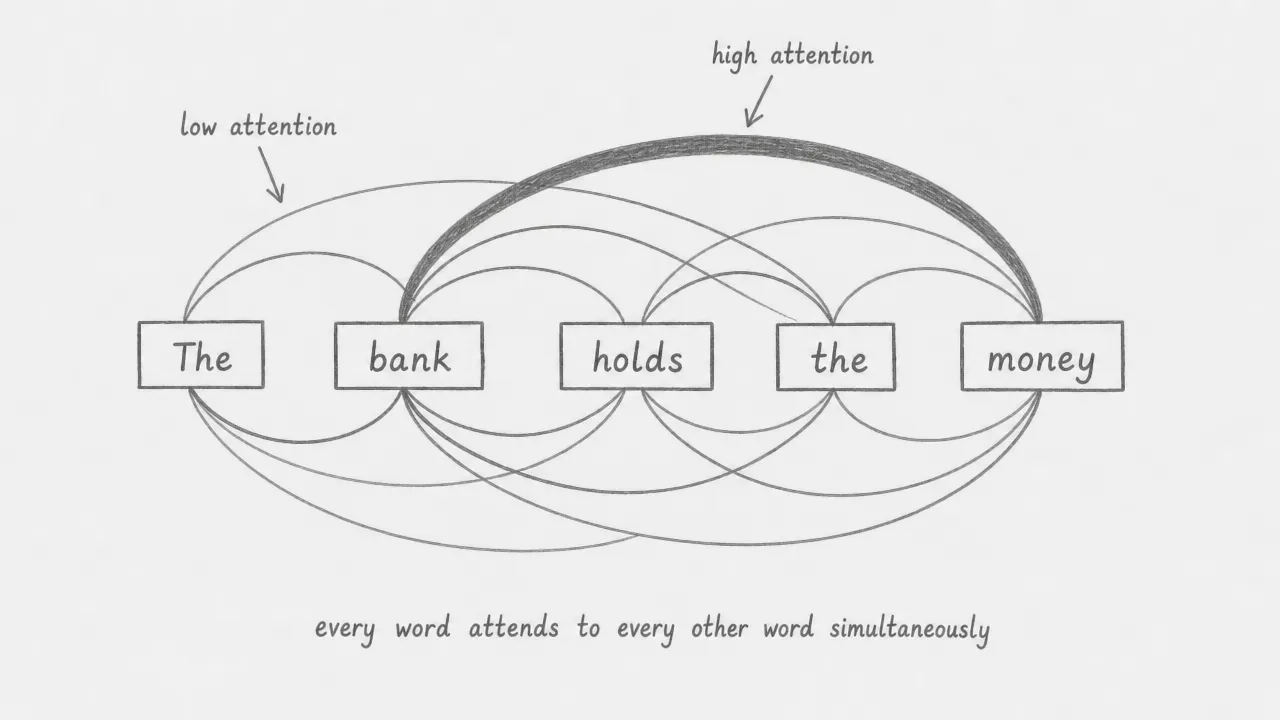
In the encoder, self-attention is unrestricted: every token can attend to every other token in both directions. For the sentence “The bank holds the money”, the word “bank” attends strongly to “money” because their relationship disambiguates the meaning of “bank” (financial institution, not riverbank). This disambiguation emerges from the attention weights, not from any explicit rule. Every word simultaneously updates its representation based on what it finds relevant in the rest of the sentence.
Six layers stacked
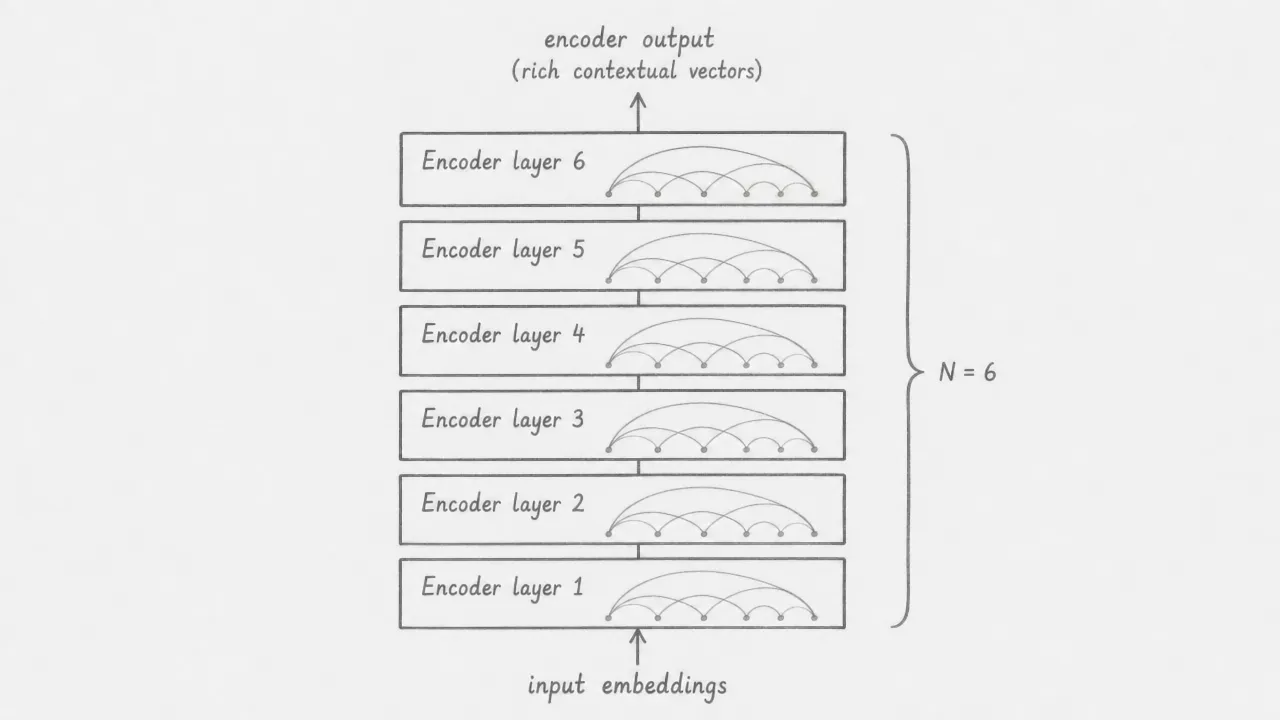
The encoder runs this process six times. Each layer takes the output of the previous layer as its input and produces a refined set of representations. Early layers tend to capture surface patterns and local relationships. Later layers tend to capture more abstract and long-range relationships. The output of layer 6 is the final encoder output: a sequence of vectors, one per input token, each informed by the full context of the sentence. These vectors are passed to every decoder layer through cross-attention.