Attention Is All You Need · Attention Is All You Need · 3 min read
Why it works
The transformer’s advantages are not incidental. They follow directly from the decision to replace recurrence with attention. Three properties explain most of the performance gain: shorter paths between tokens, full parallelism during training, and the deliberate removal of architectural assumptions that limited earlier models.
Shorter paths between distant tokens
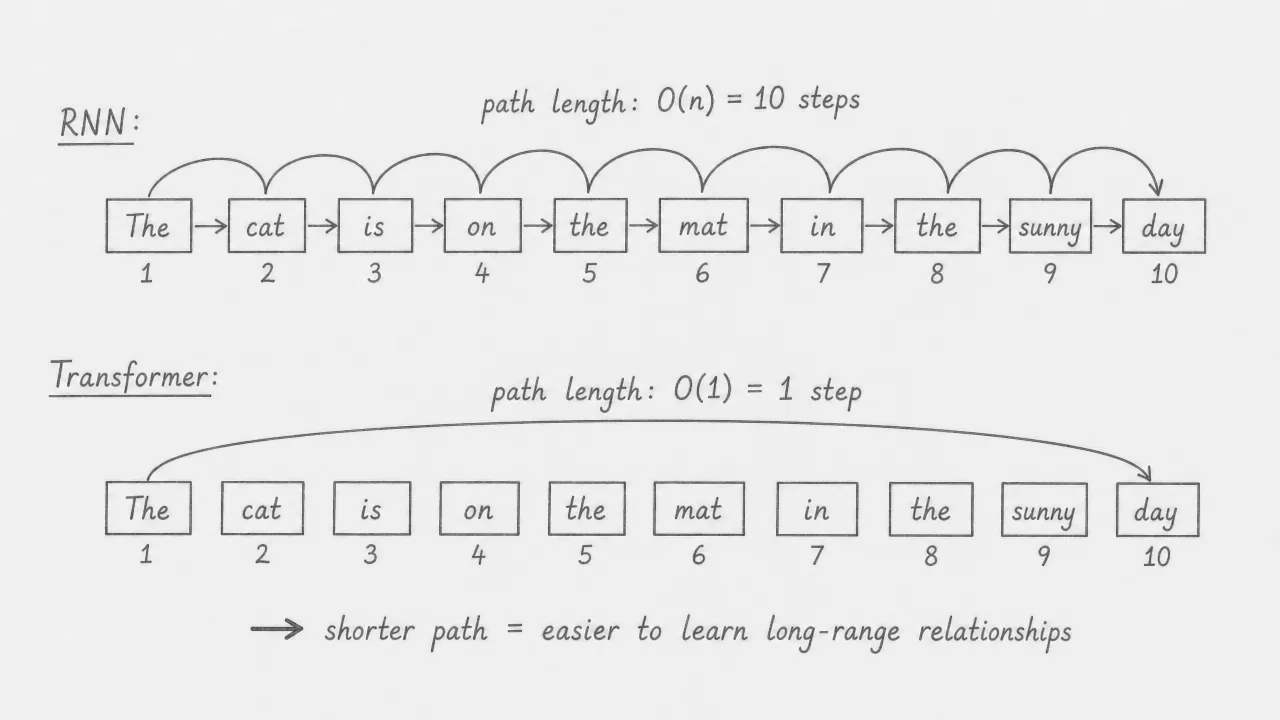
In an RNN, information from the first token must travel through every intermediate token to reach the last one. For a sequence of tokens, the path length between any two distant tokens is . In the transformer, every token is directly connected to every other token through attention. The path length between any two tokens is always , regardless of how far apart they are in the sequence. Shorter paths mean gradients flow more directly during training, making it easier for the model to learn dependencies between distant words.
Full parallelism during training
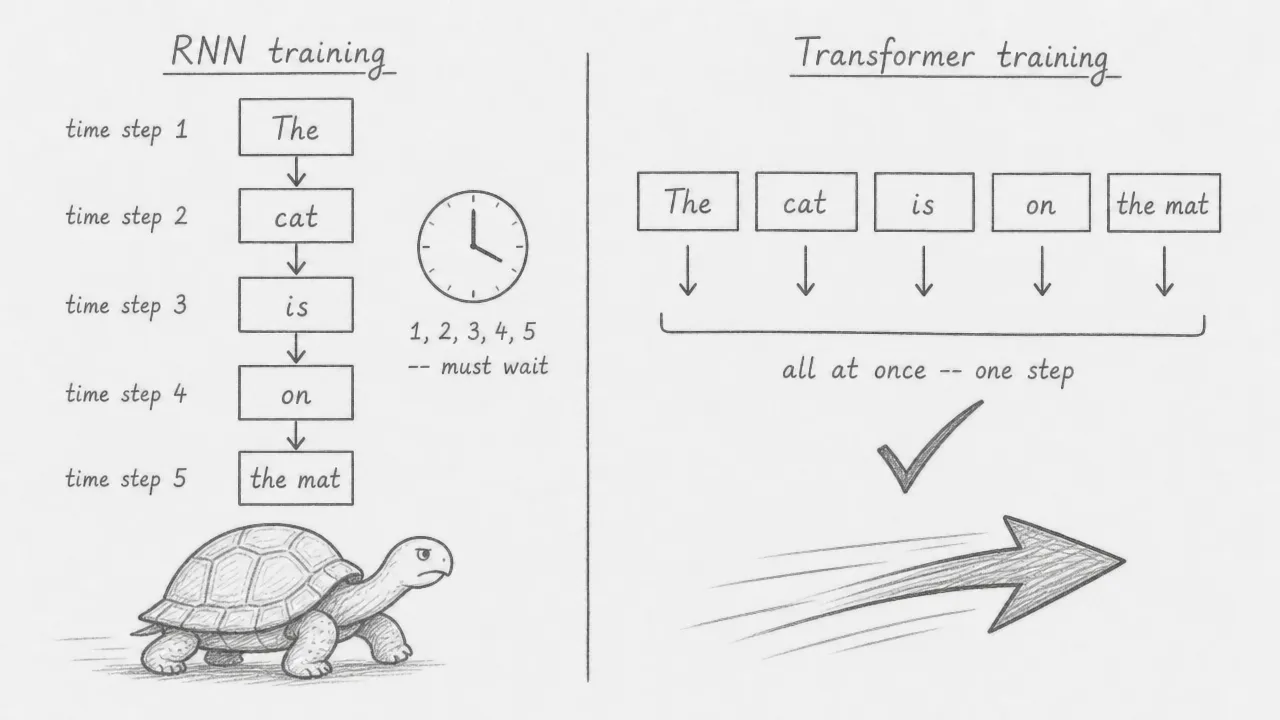
RNN training is inherently sequential: the hidden state at step depends on the hidden state at step , so no step can begin before the previous one finishes. The transformer has no such dependency. Because attention operates on the full sequence at once using matrix operations, all positions are processed in parallel on modern hardware. This means a sentence of 100 tokens takes the same number of forward pass operations as a sentence of 10 tokens. Training is dramatically faster, which makes it practical to scale to much larger datasets and model sizes.
What was removed and what was kept
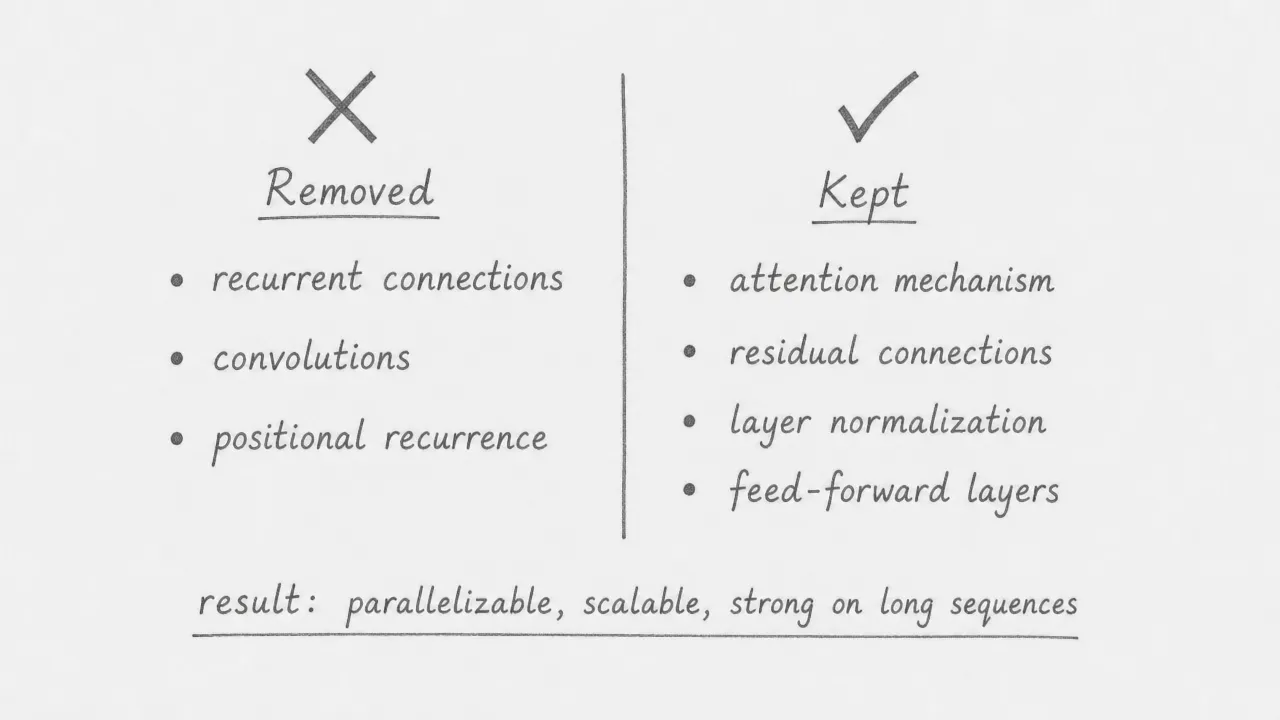
The transformer is defined as much by what it removes as by what it adds. Recurrent connections are gone, eliminating the sequential bottleneck. Convolutions are gone, removing the assumption that relevant context is always local. Positional recurrence is gone, replaced by explicit positional encodings. What remains are components that make deep networks trainable at scale: attention for global context, residual connections for gradient flow, layer normalization for training stability, and feed-forward layers for per-token transformations. The result is an architecture with no built-in bias about locality or sequence order, which makes it more general and more scalable than its predecessors.